- What We Do
- Solutions
- Learn
- Pricing
- Company
- Support
- Contact Us



Silk lets AI inference engines safely query live production databases with extreme performance, predictable latency, and no risk
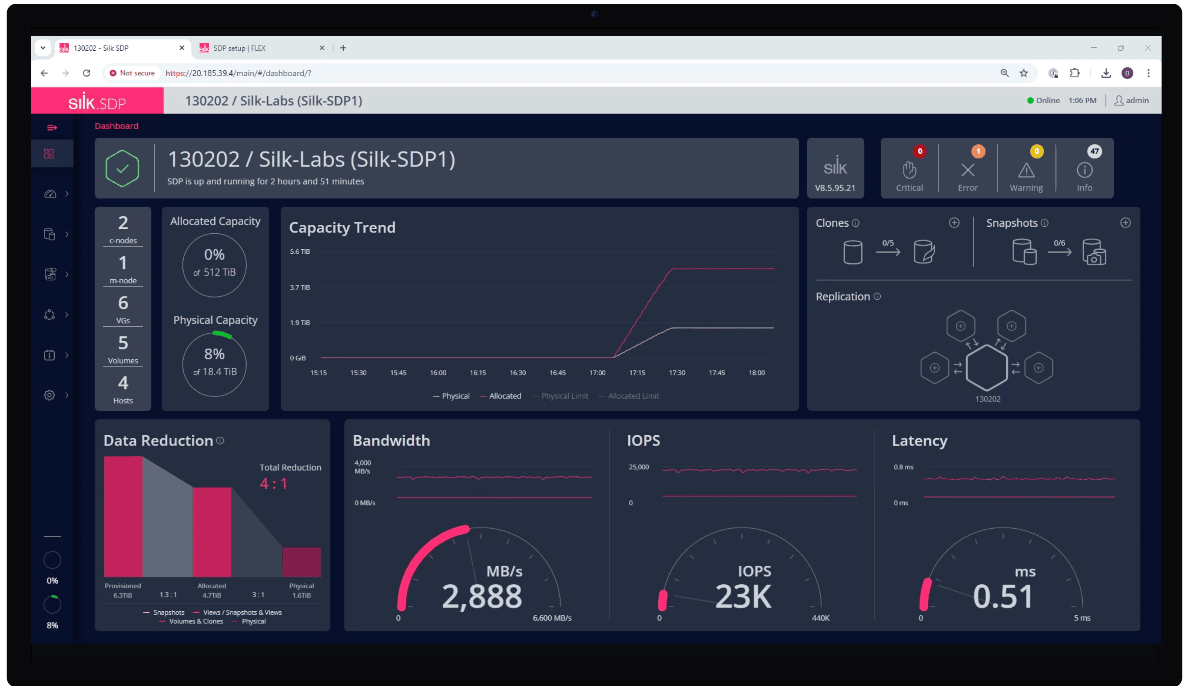
Silk removes barriers between AI inference and live production data, so you can deliver real-time intelligence at scale without compromising performance, stability, or cost.

Feed RAG pipelines and agentic AI with live production data without ETL delays or stale copies, improving model accuracy and business outcomes.
AI Inference
Absorb bursty inference workloads with consistent sub-millisecond latency and no surprise cost escalation.
Predictable Performance
As inference becomes 60-70% of AI compute spend, Silk delivers up to 10x performance gains while cutting infrastructure costs.
Cloud Cost Control
Remove the need for replicas, caching layers, and complex pipelines - run AI safely alongside mission-critical applications.
Copy Data Management